Dimensionality Reduction - Jenis dan Cara Implementasi

Apa Hubungannya Reduksi Dimensi dan Asynchronous Learning?
Sebelum masuk ke reduksi dimensi, yuk pahami dulu apa itu asynchronous learning. Dalam konteks pembelajaran mesin, asynchronous learning mengacu pada proses pembelajaran yang tidak dilakukan secara serentak atau terpusat. Contohnya seperti:
- Online learning: model belajar dari data satu per satu seiring waktu
- Federated learning: data tersebar di banyak perangkat (misalnya HP), dan model dilatih tanpa harus mengirim data ke pusat
Nah, di sistem seperti itu, penting buat kita untuk melakukan proses pelatihan seefisien mungkin. Di sinilah dimensionality reduction punya peran penting:
- Mempercepat training karena jumlah fitur yang diproses lebih sedikit
- Mengurangi kompleksitas data yang dikirim dan diproses
- Menghemat bandwidth dalam federated learning karena data yang dikirim ringkas
- Mengurangi noise, bikin model lebih stabil dan cepat converge
Jadi, sebelum data dikirim atau diproses, kita bisa reduksi dulu dimensinya pakai PCA, UMAP, dll. Ini agar asynchronous learning lebih hemat, lebih cepat, dan tetap akurat.
Apa itu Dimensionality Reduction?
Dalam dunia data, kita sering ketemu dataset yang memiliki dimensi banyak. Semakin banyak fitur, semakin ribet juga proses analisisnya, terlebih lagi susah untuk divisualisasikan. Nah, teknik Dimensionality Reduction atau Reduksi Dimensi ini berguna buat menyederhanakan data tanpa mengorbankan terlalu banyak informasi penting.
Beberapa metode populer yang sering digunakan:
- Principal Component Analysis (PCA)
- UMAP (Uniform Manifold Approximation and Projection)
- t-SNE (t-distributed Stochastic Neighbor Embedding)
Teknik ini cocok untuk:
- mengurangi noise dalam data
- percepat proses training model
- bikin visualisasi yang lebih gampang dipahami
Bagaimana Cara Kerjanya?
Bayangkan kamu punya data 3D (misalnya X, Y, Z). Ternyata, informasi pentingnya cuma ada di X sama Y. Nah, dimensi Z bisa kita buang aja biar datanya jadi 2D. Intinya, kita cuma ambil fitur yang punya kontribusi paling besar terhadap variasi data.
Kalau PCA berusaha mencari sumbu baru buat maksimalkan variansi, UMAP lebih fokus ke hubungan lokal antar data dan cocok buat peta visual yang rapi.
Studi Kasus: Dataset Penguin
Kita akan menerapkan PCA dan UMAP ke dataset Clustering Penguins Species. Dataset ini punya data morfologi dari tiga spesies penguin: Adelie, Chinstrap, dan Gentoo.
Tools yang Digunakan:
Seabornuntuk mengambil datascikit-learnuntuk preprocessing dan PCAumap-learnbuat UMAPmatplotlibdanseabornuntuk visualisasi
Tahapan Implementasi:
1. Load Data & Normalisasi
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import umap
df = sns.load_dataset('penguins').dropna(subset=[
'bill_length_mm','bill_depth_mm','flipper_length_mm','body_mass_g','species'])
X = df[['bill_length_mm','bill_depth_mm','flipper_length_mm','body_mass_g']]
y = df['species']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
2. PCA - Proyeksi Linear
1
2
3
4
5
6
7
8
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print("Explained variance (PCA):", pca.explained_variance_ratio_)
plt.figure(figsize=(6,5))
sns.scatterplot(x=X_pca[:,0], y=X_pca[:,1], hue=y)
plt.title("PCA (2D) – Penguin")
plt.show()
Hasil Visualisasi PCA:
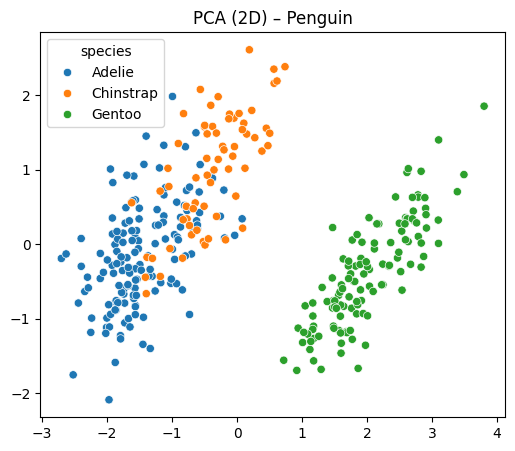
Dari hasil PCA, terlihat Gentoo lumayan terpisah, tapi Adelie dan Chinstrap masih tumpang tindih. Tapi dua komponen ini sudah menangkap hampir 88% informasi dari data asli.
3. UMAP - Proyeksi Non-Linear
1
2
3
4
5
6
7
umap_model = umap.UMAP(n_components=2, random_state=42)
X_umap = umap_model.fit_transform(X_scaled)
plt.figure(figsize=(6,5))
sns.scatterplot(x=X_umap[:,0], y=X_umap[:,1], hue=y)
plt.title("UMAP (2D) – Penguin")
plt.show()
Hasil Visualisasi UMAP:
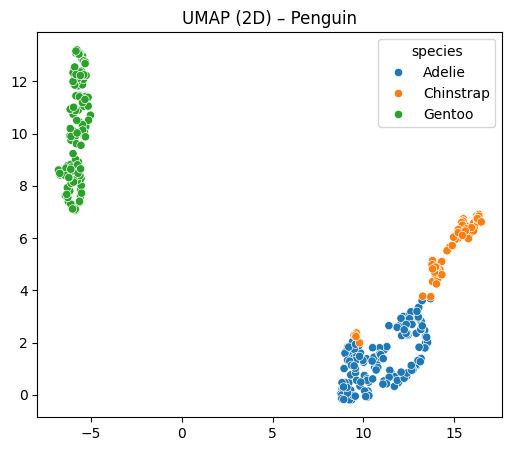
UMAP bisa memisahkan ketiga spesies dengan rapi. Cocok untuk eksplorasi data secara visual.
Perbandingan Singkat
| Aspek | PCA (Linear) | UMAP (Non-Linear) |
|---|---|---|
| Cara kerja | Proyeksi berdasarkan variansi | Berdasarkan tetangga terdekat |
| Interpretasi | Lebih gampang dipahami | Sedikit Lebih kompleks |
| Visualisasi Cluster | Lumayan jelas | Sangat jelas |
| Kecepatan | Cepat | Sedikit lebih lambat |
Kesimpulan
Dalam menangani data yang berdimensi tinggi, teknik reduksi dimensi ini wajib dicoba. Dari hasil di atas:
- PCA cocok untuk reduksi fitur secara matematis
- UMAP unggul kalau tujuannya eksplorasi atau visualisasi
Dan dalam konteks asynchronous learning, teknik ini makin berguna karena bisa mempercepat, menyederhanakan, dan mengefisienkan proses pembelajaran modern.